ヘルスチェックは、回復力を維持し、システムの継続的な運用を確保するために不可欠です。理想的には、ヘルスチェックはシステム内の問題を可能な限り早期に検出して、システムが自動的に修正するか、サービスオーナーに問題を通知して手動で解決できるようにしなければなりません。
Amazonの主任ソフトウェアエンジニアであるDavid Yanacek氏が述べているように、システムに適切なヘルスチェックを作成することは難しいかもしれません。しかし、適切に行われていれば、ヘルスチェックは効果的にサービスのダウンタイムを減らし、サービスが依存している顧客に与える影響を軽減することができます。
この記事の主な焦点は、PagerDutyのEvent Ingestion Admin(EIA)サービスのために実装されたヘルスチェックになります。EIAはイベントAPIの管理インターフェイスで、ユーザーは様々なイベントタイプの情報や、イベントが当社のシステム内に読み込まれ処理されている間のイベントの状態を見ることができます。今回は、様々なKafkaトピックからイベントを読み込み、それらのイベントをElastiCacheに保存するEIAのConsumerアプリケーションに焦点を当ててみたいと思います。このブログを読んだ後には、Kafkaに依存したシステムのヘルスチェックの書き方や、発生する可能性のある合併症への対処法が見えてくると思います。
何が不健全なのか?
EIAの問題は、Elixirロガーが新しいログを処理できないためにシステムが予期せずクラッシュした後に表面化しました。また、EIA が Kafka からの新しいメッセージの読み込みを停止する可能性が常にあることも知っていましたし、問題がより深刻になるまで気づかないことも知っていました。
このように、EIA のヘルスチェックで解決しなければならない問題が 2 つありました。(1) Kafka Consumerがforwardしていることを確認すること、(2)Elixir ロガープロセスが黙ってクラッシュすることなく動作し続けることです。これらのいずれかが機能しなくなった場合、健全性チェックは失敗し、システムを安定した状態に戻すために必要なアクションが発動されます。
問題が検出されると、問題を修正するのは非常に簡単です。次のコードは、ヘルスチェックのエンドポイントが何をすべきかをシンプルに示しています。
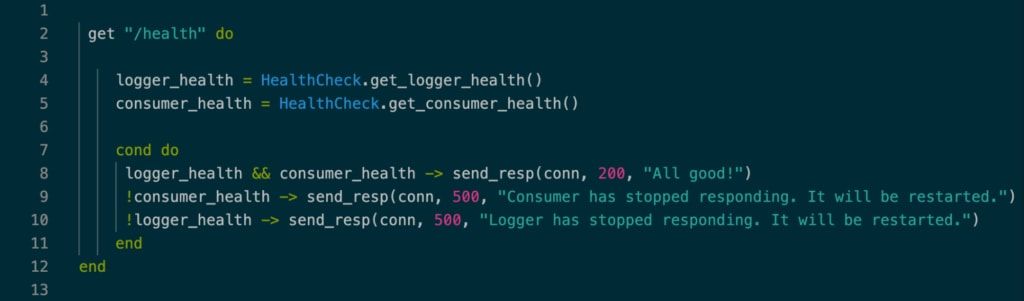
ヘルスチェックの先頭には Consul と呼ばれるネットワークツールがあります。これは、サービスの発見、ヘルスチェック、ロードバランシングなどを提供する役割を担っています。私たちのケースでは、Consul は基本的にConsumerアプリケーションの /health エンドポイントに所定の頻度(EIA の場合は 10 秒ごと)でpingを打って、システムが健全かどうかを尋ねます。ロガーとConsumerアプリの両方の健康状態が問題ない場合、サービスは200のステータスコードを返します。そうでない場合、500のステータスコードが返され、回復プロセス(サービスの再起動)を開始するようにConsulに合図します。
ナイーブなアプローチ
EIA は多数の Kafka トピックを読み込み、各トピックには 64~100 のパーティションがあります。各トピックのConsumerごとに別のコンテナをスピンアップし、それぞれが独自のヘルスチェックを持ち、ヘルス状態に基づいて個別に再起動することができます。
まず、Elixir GenServer(汎用サーバ)を作成することから始めました。GenServerは、アプリケーション内の他のプロセスと通信しながら、コードを非同期に保存、状態表示、実行できるプロセスです。特に、ヘルスチェックのGenServerは、イベントの現在の状態を更新し、現在の状態に基づいてアプリが健全かどうかを判断する役割を担っています。
これを行うためには、いくつかのステップを踏まなければなりませんでした。イベントが取り込まれて処理されるたびに、GenServerの状態は、イベントが正常に処理された最後の時間を示すタイムスタンプで更新されます。Consulが /health エンドポイントにpingを打つとき、最新のタイムスタンプが現在の時刻から10秒以内の閾値内にあれば、Consumerアプリは健康とみなされます。
このアプローチにはいくつかの問題がありました。2つのConsumerが同じ速度でメッセージを読み込んで処理することはありません。例えば、incoming_events トピックと failed_events トピックを考えてみましょう。incoming_events トピックは高スループットのストリームです。健全なトピックを判断するための閾値が20秒だったとすると、健全なトピックであることをヘルスチェックで判断することができます。
それに比べて、failed_eventsトピックは20秒以内にトラフィックが発生しない可能性があります。ヘルスチェックは、その時間が経過すると failed_events のConsumerは不健康であると考えるでしょうが、これは必ずしも真実ではありません。Consumerごとに異なる閾値を設定することもできましたが、非運用環境では、長時間トラフィックが全くない可能性が高いです。そうなると、EIAが意味もなく再起動され続けることになります。
一度失敗したら、試してみて、もう一度試してみる
時間ベースのアプローチでは十分ではないことがわかったので、次のアイデアは Kafka のConsumerオフセットを利用することでした。使用するオフセットには、現在の(最新の)オフセットとコミットされたオフセットの 2 種類があります。現在のオフセットはトピックに送信された最後のメッセージを指し、コミットされたオフセットはConsumerによって正常に処理された最後のメッセージを指します。
Consumerアプリが正常に動作しているかどうかを確認するために、forwardしているかどうかを確認したいと考えました。最新のオフセットが移動している(つまり、新しいメッセージを読み込んでいる)ので、コミットされたオフセットも同様に移動している(つまり、新しいメッセージを処理している)ことになります。このソリューションでは、メッセージがいつ入ってきたかどうかは問題ではないので、最初のアプローチからの問題が解決されます。
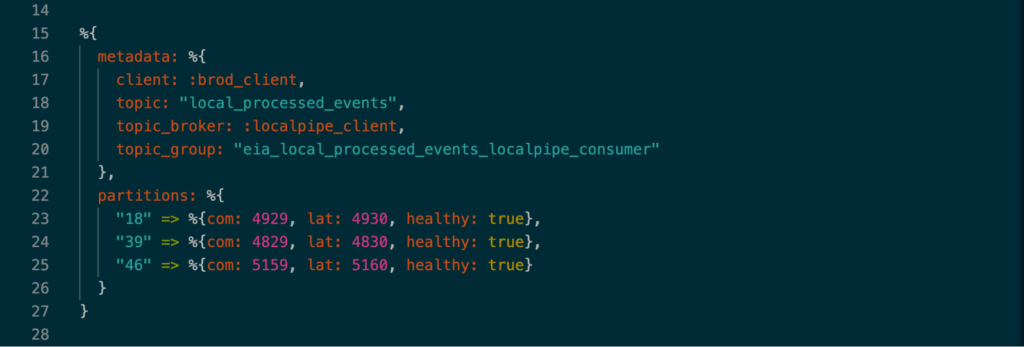
このソリューションを実装するために、ヘルスチェックのGenServerは、より複雑な情報をステートに保存する必要がありました。以下はステートを抜粋したものです。
ステートには、メタデータ(異なるオフセットを取得するために必要)とパーティション情報という2つの主要なコンポーネントが保存されています。各パーティションには、コミットされたオフセットと最新のオフセット、そしてパーティションの健全性を決定するフラグが格納されています。新しいイベントが入るたびに、GenServer は新しいオフセットで更新されます。ネットワークツールがヘルスチェックのエンドポイントにpingすると、ステートはすべてのパーティションが不健康であるかどうかをチェックするために繰り返されます。もしそうであれば、Consumerコンテナは再起動されます。
プリプロダクション環境でテストを実行した結果、ヘルスチェックは正常に機能していました。これらの変更を本番環境に適用した後、GenServer が本番環境のトラフィックに追いつけず、ヘルスチェックプロセスがクラッシュし続け、アプリケーションが不安定な状態になっていることがすぐに明らかになりました。私たちは変更を元に戻し、振り出しに戻りました。
3度目のチャンス
以前のアプローチでの最大のボトルネックは、EIA が処理しなければならないトラフィックの量でした。幸いなことに、その答は手元のソリューションからそう遠くないものでした。各イベントの後にGenServerの状態を更新する代わりに、ヘルスチェックは10秒ごとに各パーティションを更新してチェックすることができました。これがどのように実現されたのか、ヘルスチェックの主な機能を見てみましょう。
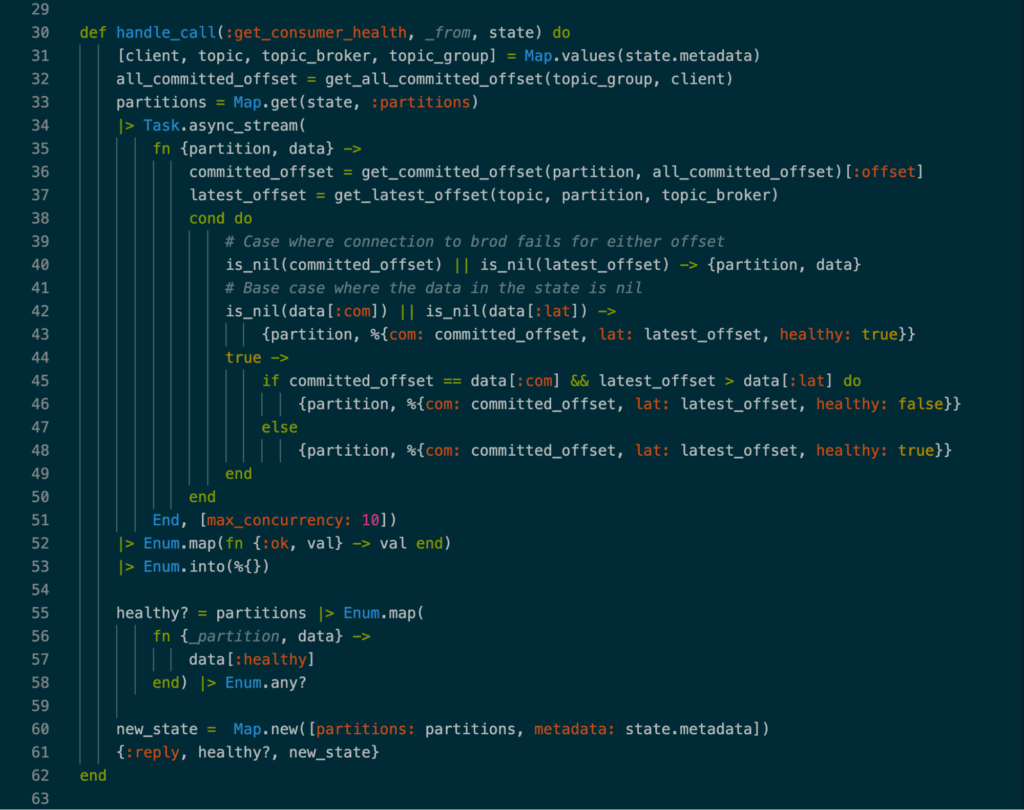 画像3: ヘルスチェックの実装
画像3: ヘルスチェックの実装
GenServerが初期化されると、状態のパーティションデータはNULLに設定されます。最初にConsulがヘルスエンドポイントにpingを打つと、GenServerは各パーティションのコミットされたオフセットと最新のオフセットをフェッチしてステートにセットします。それ以降の実行では、Kafka の各パーティションの現在のコミットされたオフセットと最新のオフセットが、ステートに保存された古いオフセットと比較されます。forwardしている場合は、パーティションの健康状態がtrueに更新され、ステートがオフセットで更新されます。各パーティションを見て更新すると、ステートは反復され、トピック全体が健全かどうかをチェックし、適切な値をConsulに返します。
この方法では、EIA が消費するイベントの数は問題にならないので、健康チェックの GenServer は以前よりもかなり少ない作業をすることになります。これは本番に向けてプッシュバックされ、無事に動作しました!
別れの想い
プロセス全体を通して私が得た重要なポイントの1つは、問題に対する答が最初は必ずしも明らかではないということです。システムとその要件によっては、それが正しいものになるまでに何度も反復する余地があります。Kafka を初めて使う人にとって、システムが健全かどうかを判断するためにツールを活用する創造的な方法を考え出すことは、興味深く、最終的には非常にやりがいのあることでした。もしあなたがKafkaに依存したサービスで同じようなことをしようとしているのであれば、私たちが学んだ教訓を共有して、あなたのプロセスがどのように進んだかを聞いて、あなたを助けたいと思います。
本記事は米国PagerDuty社のサイトで公開されているものをDigitalStacksが日本語に訳したものです。無断複製を禁じます。原文はこちらです。
 カテゴリー :インテグレーション&ガイド
カテゴリー :インテグレーション&ガイド

