共著者:PagerDutyデータサイエンティストVI、Chris Bonnell氏
引き続き、IAG(Intelligent Alert Grouping)の活用・改善方法について、第3回目をお届けします。最初の投稿では、インテリジェントアラートグループ化機能を紹介しました(こちら)。2回目の投稿では、IAGがどのようにマージを使用してアラートをグループ化するのかを説明しました(こちら)。本日は、IAGのマッチングを向上させるためにアラートタイトルを使う方法について説明します。
アラートタイトルが表示される場所 - 再確認
アラートがプラットフォームでトリガーされると、eメール、テキスト、またはアプリ自体からのプッシュ通知など、いくつかの経路で通知が行われることがあります。どの経路であっても、表示される最小限の情報は、アラート番号、サービス、およびアラートタイトルです。これは、いくつかの注目すべき場所に表示されます。アラートの受信方法によっては、これらの一部または全部が見慣れたものかもしれません。緊急度レベル(例:高)は、連絡方法を決定するために使用されますが、目に見える形で表示されないことに注意してください(ただし、インシデントの詳細には表示されます)。
電話のプッシュ通知とテキスト通知
例えば、iPhoneのロック画面を見てみましょう(同じインシデントについてのテキストメッセージ通知や電話着信)。
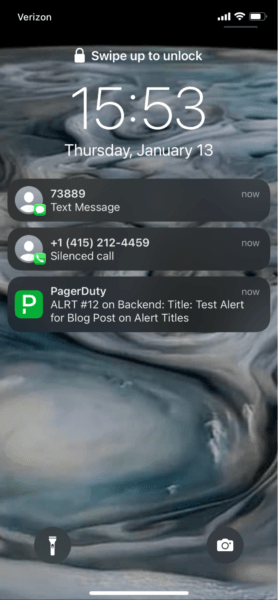
これはブログ投稿のために全てのチャンネルにアラートをプッシュしています。ここでは、アラートのタイトル、番号、サービスが表示されていることが分かります。テキストメッセージも似たような感じです。

メール通知
これらは少し違っているように見えます。メールの件名にはあまり詳細が書かれていませんが、メッセージの本文にはアラートの詳細が記載されています。
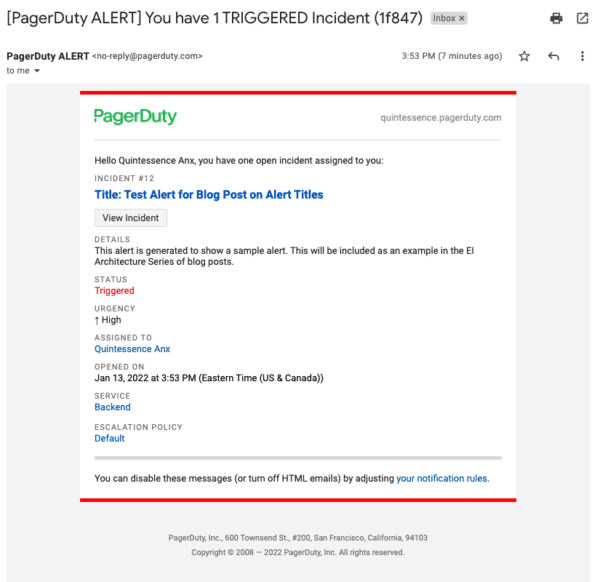
なぜ、アラートタイトルの表示場所を見直すのですか?
私のような方なら、実際の状況やサービスに関するアラートタイトルや説明文を書いていたときは、人間の脳に最適化させていたのではないでしょうか。証拠は上にも表れています。このアラートタイトルはブログ記事のタイトルのようだし、文頭に「Title」という識別子を強引に含んで、それが表示される場所を強調しています。これは人間のためのもの。読者の皆さんが画像から情報を読み取る際に、私が特定の部分に注目してもらいたくて故意にやりました。
もし、人間以外のために設計するとしたら?例えば、機械学習に適した設計ならどうでしょう?機械学習について知っていることや学んだことを何でも取り込み、それらを活用しようとメッセージを歪め始めるでしょう。
私が皆さんにお伝えしたいのは、このことです。インテリジェントアラートグループの体験を向上させるために機械学習を取り入れる際にも、人間のことを念頭に置く必要があるということです。
アラートタイトルを活用する
人のためにアラートタイトルを構築するとき、忘れてはならないことがあります。
-
簡潔であること。ご覧の通り、プッシュ通知もテキスト通知も文字数制限が短いです。
- OSやウェブブラウザーによって制限が異なります。例えば、Androidの場合、プッシュするタイトルの文字数制限は65文字で、さらに説明文の文字数制限は240文字です。iOSの場合は、タイトルと説明文を合わせて178文字となっています。
-
明確であること。タイトルが分かりにくくなったり、何も伝わらなかったりするほど簡潔であってはなりません。
-
タイトル欄を優先するあまり、他の欄をおろそかにしないこと。
- ウェブインターフェイスと同様に、PagerDutyモバイルアプリでは、他のインシデント、そのサービス、その説明を含む完全なインシデント情報を利用することができます。最初に表示されるからといって、タイトルフィールドに情報を盛り込みすぎないでください。
これらの詳細については、インシデントレスポンス運用ガイドの「アラート発信の原則」のページをご覧ください。
機械学習では、以下のことに注意しましょう。
- 識別性と頻度を上手に利用する。
- データモデルは(人間と同じようには)読むことができない。
- データモデルは意図を推論することができない。
その理由は、機械が「自然言語処理」と呼ばれるものをどのように行っているかを理解するためです。自然言語処理とは、スペルチェックや文法チェッカーが「it's」と「its」を区別して著者に通知したり、オートコレクトがどの単語と活用、どの形式(活用、自然下降)を提案するかを知るためのものです。アラートタイトルに適用される自然言語処理では、タイトルを匿名化し(詳細は後述)、「文トークン化」と「単語トークン化」というプロセスでそれぞれ文と単語に分解し、単語を見出し語化(レンマ化)して、最終結果を頻度の決定と他のアラートとの相関性の検索に使用します。
匿名化から始めると、例えば特定のIPアドレスをxx.xx.xxに置き換えるように、そうでなければあまりにも一意な情報をその情報のパターンに置き換えることが目的です。このテキストは、一意な情報によって本来関連するはずのタイトルが関連しなくなることを防ぎます。関連する可能性のあるコンテキストが完全に削除されるわけではありません。レンマ化とは、活用語や屈折変化をレンマと呼ばれる基本形に単純化する工程のことです。再び例で説明します。{“dogs”, “dog’s”, “dogs’”, “dog”}は全て“dog”にレンマ化され、同様に{“is”, “are”, “be”, “were”}は”be”にレンマ化されます。つまり、“The dog's bones.”と“The dogs' bones.”のような文は、この段階でどちらも{“the”, “dog”, “bone”, “.”}にレンマ化されるのです。
この時点で、インテリジェントアラートグループモデルは、N-gram(N個の単語のグループ)とインシデント言語のパターンに関する知識の両方を使用して、アラートタイトルから情報を抽出し、意味のある相関関係を作成します。前回の記事で紹介した例をもう一度見てみましょう。
- 最初のパターン
- memory usage high (> N %) on server $NAME in region $REGION
- 2つ目のパターン
- memory usage on host is high (> N %)
既にN %と$NAMEで少し匿名化しましたが、これらのタイトルにあるものをトークン化する練習をしてみましょう。
- トークン化、レンマ化された最初のパターン。
- {“memory”, “use”, “high”, “(“, “>”, “N”, “%”, “)”, “on”, “server”, “$NAME”, “in”, “region”, “$REGION”}
- トークン化、レンマ化された第2パターン。
- {“memory”, “use”, “on”, “host”, “be”, “high”, “(“, “>”, “N”, “%”, “)”}
パターンが意味することの影響を考えると、2番目のアラートでは、そこに置かれた値によって変化する唯一の用語はNです。もし閾値が現在のメモリー使用量ではなく、一貫したものであれば、Nは全く変化しないか、タイトルに表示される値が1つか2つしかない可能性があります。それに対して、最初のアラートのタイトルには、サーバー名とその地域の一意性がより強くなっています。つまり、用語は1つまたは全く変化しないのではなく、3つの変化する用語があるわけです。言語処理装置に関する限り、2番目のパターンのアラートは1番目のパターンよりも相関関係がある可能性がはるかに高いです。
これからの方向性
アラートのタイトルを作成する際には、人間と機械学習の両方を考慮することが重要です。人間はアラートやインシデントの詳細情報を利用して追加のコンテキストや情報を得ることができますが、インテリジェントアラートグループではタイトルフィールドのみを使用するため、機械学習の最適化を若干意識するとよいでしょう。自然言語処理の基本については、Towards Data Scienceブログの「Introduction to Natural Language Processing for Text」ブログ記事をご覧ください。一般的にアラートやインシデントに含めるべき情報についてのベストプラクティスは、当社のインシデントレスポンス運用ガイドをご覧ください。
この記事はPagerDuty社のウェブサイトで公開されているものをDigital Stacksが日本語に訳したものです。無断複製を禁じます。原文はこちらです。
 カテゴリー :インシデント&アラート
カテゴリー :インシデント&アラート

