今年もこの時期がやってきました。PagerDutyがAWS re: Invent 2022のためにシン・シティに戻ってきます!このグローバルコンファレンスでは、あらゆる規模の企業が参加し、クラウドの近代化、自動化、回復力をテーマに議論が行われます。現在の経済状況において、企業は常時接続のデジタル体験を顧客に提供しながら、運用を拡張し、コストの最適化を求めています。Automatonは、運用とコストの効率化をサポートする上で重要な役割を果たします。今年、私たちはre:Inventの会場に新しいソリューションを持参できることをうれしく思っています。 Automated Diagnostics for AWSは、エンジニアリングチームがより多くの時間をイノベーションに費やし、中断しないよう支援します。また、re:InventのPlatinum Sponsorとして、AWSとの長期的な関係を深め、お客様と共同で自動化されたCloudOpsを提供できることを誇りに思っています。
クラウドは世界を食べている
Gartnerによると、「2023年までに、企業の全ワークロードの40%がクラウドインフラとプラットフォームサービスに展開され、これは2020年の20%から増加する」とのことです。この言葉は、サービスとバックエンドインフラのさらなるデジタル化を目指す企業にとって、クラウドの導入が引き続き最重要課題であるという現実をより突きつけています。AWSは、これまでにないスケール、アジリティ、イノベーションのスピードを提供しますが、チームは、システム、プロセス、組織にわたって複雑性が増し、依存関係がますます大きくなっていることに直面します。この複雑な状況は、収益はもちろんのこと、顧客と従業員のエクスペリエンスを危険にさらす恐れがあります。
組織がクラウドに移行し、クラウドネイティブアーキテクチャを展開するにつれ、複雑さが増すと、より多くの(費用のかかる)インシデントを引き起こす可能性があります。多くの企業は、相互に接続された複数のサービス(多くは一時的に存在する)を含む複雑なクラウドアーキテクチャを使用しており、それらは異なるアベイラビリティゾーンやアカウントにまたがって展開されています。インシデントが発生すると、根本的な原因や、適切なアクセス権限や専門知識を持つ人を理解できないまま、解決に長い時間がかかることがあります。これは、多くのエスカレーションが発生し、開発者が価値の高い仕事から引き離されることを意味します。
インシデントは高くつくものです。大手小売業者の場合、サイトが1分ダウンするごとに、1分当たり20万ドル以上の売上が失われる可能性があります。また、インシデントが発生すると、エンジニアは新機能の構築やイノベーションに集中する代わりに、問題の解決に取り組むため、生産性コストが発生します。インシデントが原因で、あるいはインシデント発生中に顧客体験が低下すると、ブランドの評判という形でさらにコストがかかる可能性があります。これらの要因を全て合わせると、インシデントがもたらすコストは、想定していたよりもはるかに高くなります。
レジリエンス(回復力)の重要性
顧客がデジタル体験をほとんど中断することなく楽しむためには、レジリエンスが不可欠です。しかし、現実は厳しいものです。物事が壊れ、サービスが停止することは避けられません。それは誰にでも起こることです。本当に重要なのは、どれだけ早く復旧してサービスを再開できるか、また、今後同様の事態が発生しないようにできるかです。ハイブリッド・インフラストラクチャーを完全に可視化し、問題の迅速な検出・診断は、ビジネスと全てのサービスを継続するために必要不可欠です。
レジリエンスはただ起こるのではなく、責任の共有です。お客様は、インシデントに耐え、迅速に対応できるように、インフラ、運用、および人員を設定する必要があります。チームが自分たちのサービスを構築し所有することで、明確な所有権と説明責任を定義することは、集中したリアルタイムのインシデント対応を確保するために不可欠な要素です。
PagerDutyは、エンドツーエンドのインシデント対応と高度な自動化機能によってチームを強化し、いつでも迅速かつ正確に、正しい対応を指揮します。プロセスの自動化により、インシデントの迅速な診断と解決が可能になり、エスカレーションの回数とMTTRが大幅に削減されるため、エンジニアリングチームは継続的な改善とイノベーションに集中できるようになります。
人間が多く、時間がない
AWSのお客様の最新のクラウドアーキテクチャーは、市場で利用可能な約250のAWSサービスと2万5000のSaaSワークフローに、自社開発のソフトウェアやその他のレガシーシステムが組み合わされたものです。
このような複雑なクラウド環境でインシデントが発生した場合、根本原因を特定し、依存関係の中から他の可能性を排除し、誤検出をチェックするために、クラウドスタックの専門知識をフル活用することがしばしば必要とされます。このため、最前線のレスポンダーは、複数の専門エンジニアにエスカレーションして診断を依頼し、最終的な解決者を決定する必要がある場合があります。
最前線のレスポンダーは、AWS環境での診断内容を収集するノウハウやアクセス権がないことが多いです。最前線のレスポンダーの多くはジェネラリストであり、サービスにおける特定の問題を診断するために必要な調査に関する、技術的な知識を持ちません。また、セキュリティーポリシーにより、技術的な調査を実行するためのスーパーユーザーアクセスもありません。
このため、最初のレスポンダーは通常、インシデントのトリアージに必要なデータを得るために複数の専門家にエスカレーションしなければならず、インシデントの解決に多くの時間を費やし、より多くのチームメンバーに支障をきたします。深刻な機能停止の場合、インシデントの解決にかかる時間を不必要に長びかせ、エンジニアを価値の高い作業から遠ざけてしまい、停電の全体的なコストを増加させることにつながります。自動化は、インシデントを迅速に解決するだけでなく、インシデントを自分で解決するために必要な診断データを最初のレスポンダーに提供し、貴重なエンジニアリング時間を保護するという重要な役割を果たすのです。
Automated Diagnostics for AWS
Automated Diagnostics for AWSを使用すると、インシデントレスポンダーが自分でインシデントのトリアージを迅速に行い、ヘルプをエスカレーションする必要性を減らし、顧客に対する解決を迅速化し、運用効率を向上させます。PagerDutyのAutomated Diagnostics for AWSでは、Amazon EC2、AWS Lambda、Amazon ECS、Amazon RDSなど、よく使われるサービス向けの診断ジョブテンプレートがあらかじめ用意されています。お客様は、これらのテンプレートジョブを特定の環境で動作するように簡単に設定し、ワークフロー内の診断ステップを拡張できます。また、Automated Diagnostics for AWSでは、AWS向けの独自の診断ジョブや、PagerDuty Incident Response内のレスポンダーが呼び出したり、PagerDuty Event Intelligenceがトリガーする緩和・修復のための修正オートメーションの迅速な設計が可能です。
カスタマーサービスチームとステークホルダーは、リアルタイムのステータス情報によって調整され、よりよいカスタマーサポート体験を提供できます。自動化により、MTTRを25分短縮し、インシデントの解決に必要な人数を減らし、エスカレーションの回数を40%減らすことで、社内チームがより効率的に運営できるようになり、時間とコストを削減しながらカスタマーエクスペリエンスを向上させられるのです。
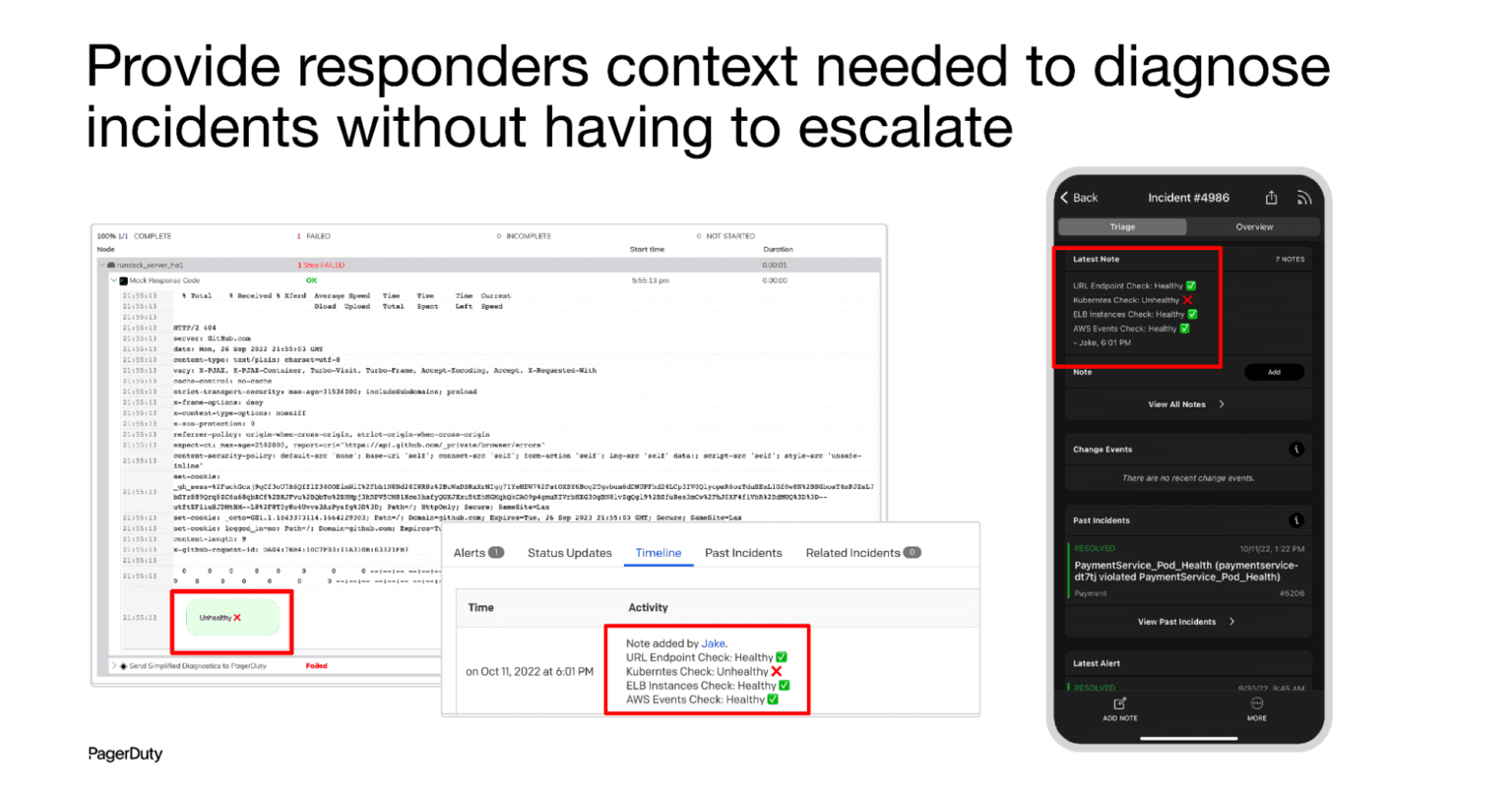
Automated Diagnostics for AWS
- インシデントのトリアージ、ミティゲーション、および解決を行う力を持つ最初のレスポンダーを強化し、MTTR を全面的に改善します。
- あらかじめ組み込まれたジョブテンプレートと、重要なAWSツールやサービスへのプラグイン統合により、エンジニアへのエスカレーションを削減します。
- AWS環境におけるインシデントレスポンスの効率を継続的に向上させ、エンジニアに時間を還元できます。
Automated Diagnostics for AWSの詳細についてはこちらをご覧ください。
この記事はPagerDuty社のウェブサイトで公開されているものをDigital Stacksが日本語に訳したものです。無断複製を禁じます。原文はこちらです。
 カテゴリー :インテグレーション&ガイド
カテゴリー :インテグレーション&ガイド

